
검증
NumberterKit이 그럼 기존의 Race Condition 문제를 해결했는지와 실제로 성능은 어느정도 개선되었는지에 대해 분석하였습니다.
테스트 케이스를 통한 검증
앞서 수동 테스트로 동작을 확인했지만,
신뢰할 수 있는 결과를 보장하기 위해 XCTestCase를 통한 자동화 테스트도 함께 진행하였습니다.
다음과 같이 Race Condition 재현 테스트를 테스트 케이스로 등록하여,
매번 일관된 결과가 출력되는지 검증했습니다.
import XCTest
final class FormatterProviderTests: XCTestCase {
func testDecimalFormatterRaceSafe() {
let number = NSNumber(value: 1234.5678)
let expectedResults = [
0: "1,235",
1: "1,234.57"
]
let iterations = 20
DispatchQueue.concurrentPerform(iterations: iterations) { i in
let digits = (i % 2 == 0) ? 0 : 2
let formatted = FormatterProvider.decimal(fractionDigits: digits)
.string(from: number)
XCTAssertEqual(formatted, expectedResults[i % 2])
}
}
}
테스트 결과, 모든 스레드에서 요청한 자리수에 맞는 일관된 출력이 검증되었습니다.
성능 테스트
다음으론 SpinLock 기반 공유 Formatter와 매번 새 인스턴스를 생성하는 방식의 성능 차이를 테스트해 보았습니다.
테스트 환경
- 싱글 스레드 10,000회 호출
- 멀티 스레드 (10개의 스레드 × 1,000회 호출)
두 가지 환경에서
- FormatterProvider.decimal(fractionDigits:) (SpinLock 기반 공유 인스턴스)
- FormatterProvider.newDecimal(fractionDigits:) (매번 새 인스턴스 생성)
을 비교하였습니다.
다음은 테스트 환경에 대한 정보입니다.
| 테스트 기기 | MacBook Pro (Apple Silicon M1) |
| 테스트 도구 | Xcode XCTest.measure |
| 테스트 횟수 | 기본 10회 반복 측정 |
| 성능 지표 | 평균 실행 시간 (Wall Clock Time) |
| 비교 대상 | 공유 인스턴스 방식 vs 매번 새 인스턴스 생성 방식 |
measure란 해당 메서드를 10번 실행한 후 평균 실행 시간을 알려주는 메서드입니다.
싱글 스레드 테스트 결과
먼저 싱글 스레드에서 10,000번을 호출했을 때의 성능 결과입니다.
// MARK: 싱글 스레드
/// NumberFormatter 생성
func testFormatterCreationPerformance() {
measure {
for _ in 0..<10_000 {
let formatter = NumberFormatter()
_ = formatter.string(from: 1234.5678)
}
}
}
/// 공유 인스턴스
func testSharedFormatterWithSpinLockPerformance() {
let number = NSNumber(value: 1234.5678)
measure {
for _ in 0..<10_000 {
_ = FormatterProvider.decimal(fractionDigits: 2).string(from: number)
}
}
}
| SpinLock 기반 공유 Formatter | 0.0796 (Sec) |
| 매번 새 인스턴스 생성 | 0.327 (sec) |
제가 구현한 SpinLock 기반 공유 방식이 약 4배 이상 빠른 성능을 보여주었습니다.


멀티 스레드 테스트 결과
다음은 10개의 멀티 스레드에서 각 1,000회씩 호출했을 때의 성능 결과입니다.
// MARK: 멀티 스레드
/// NumberFormatter 생성
func testNewFormatterCreationPerformanceMultiThread() {
let number = NSNumber(value: 1234.5678)
let iterations = 10_000
measure {
DispatchQueue.concurrentPerform(iterations: 10) { _ in
for _ in 0..<(iterations / 10) {
let formatter = NumberFormatter()
formatter.numberStyle = .decimal
formatter.minimumFractionDigits = 2
formatter.maximumFractionDigits = 2
formatter.groupingSeparator = ","
formatter.locale = Locale(identifier: "ko_KR")
_ = formatter.string(from: number)
}
}
}
}
/// 공유 인스턴스
func testSharedFormatterPerformanceMultiThread() {
let number = NSNumber(value: 1234.5678)
let iterations = 10_000
measure {
DispatchQueue.concurrentPerform(iterations: 10) { _ in
for _ in 0..<(iterations / 10) {
_ = FormatterProvider.decimal(fractionDigits: 2).string(from: number)
}
}
}
}
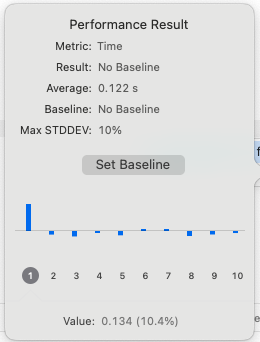
| SpinLock 기반 공유 Formatter | 0.122 (Sec) |
| 매번 새 인스턴스 생성 | 0.265 (Sec) |
제가 구현한 SpinLock 기반 공유 방식이 약 2배 이상 빠른 성능을 보여주었습니다.

정리하며
이번 테스트를 통해 SpinLock 기반 공유 Formatter 방식이 성능적으로도 충분히 유리하다는 것을 확인할 수 있었습니다.
- 싱글 스레드: 객체 생성 비용 절감으로 최대 4배 성능 향상
- 멀티 스레드: 락의 오버헤드에도 불구하고 최대 2배 성능 향상
이 결과는 락 사용이 무조건 느리다는 일반적인 편견과 달리,
적절한 상황에서는 락이 성능과 안정성 모두를 잡을 수 있다는 가능성을 보여주었습니다.
앞으로도 성능과 구조의 균형을 고민하며 최적의 설계 방안을 찾기 위해 계속 실험해 나가겠습니다.
'iOS > NumberterKit' 카테고리의 다른 글
| [NumberterKit] 성능 테스트 - 락 기법별 상세 분석 (0) | 2025.07.03 |
|---|---|
| [NumberterKit] 성능 테스트 - 스레드 수별 상세 분석 (0) | 2025.06.15 |
| [NumberterKit] Formatter 최적화: SpinLock 적용기 (0) | 2025.05.09 |
| [NumberterKit] NumberterKit을 만들게 된 계기와 컨셉 (0) | 2025.04.20 |